
Introduction to Computing Power Architecture
In order to ensure the universality and ease of use of AI computing power, Spacemit has built a CPU with AI fusion computing power by extending AI instructions based on the standard RISC-V core. This fusion processor with complete CPU functions and powerful AI computing power is named the Intelligent Computing Core. The complete CPU functions ensure the universality and ease of use of AI computing power, allowing the Intelligent Computing Core to be easily integrated into the open-source ecosystem. In addition, the processor follows the concept of the IME group in the RISCV community and reuses the Vector register resources for AI computing, injecting powerful AI computing power into the Intelligent Computing Core at a minimal hardware cost. The powerful AI computing power can bring more than 10 times the performance improvement to AI applications.
1. Composition of Computing Power
In AI computing, Scalar computing power, Vector computing power, and Matrix computing power will be used. Spacemit follows the RISC-V community standards to the greatest extent and only extends the instructions for matrix computing power. X60 is the first generation of Intelligent Computing Core implemented based on the above architectural concept, and Matrix computing power for the int8 data type is added to this core.
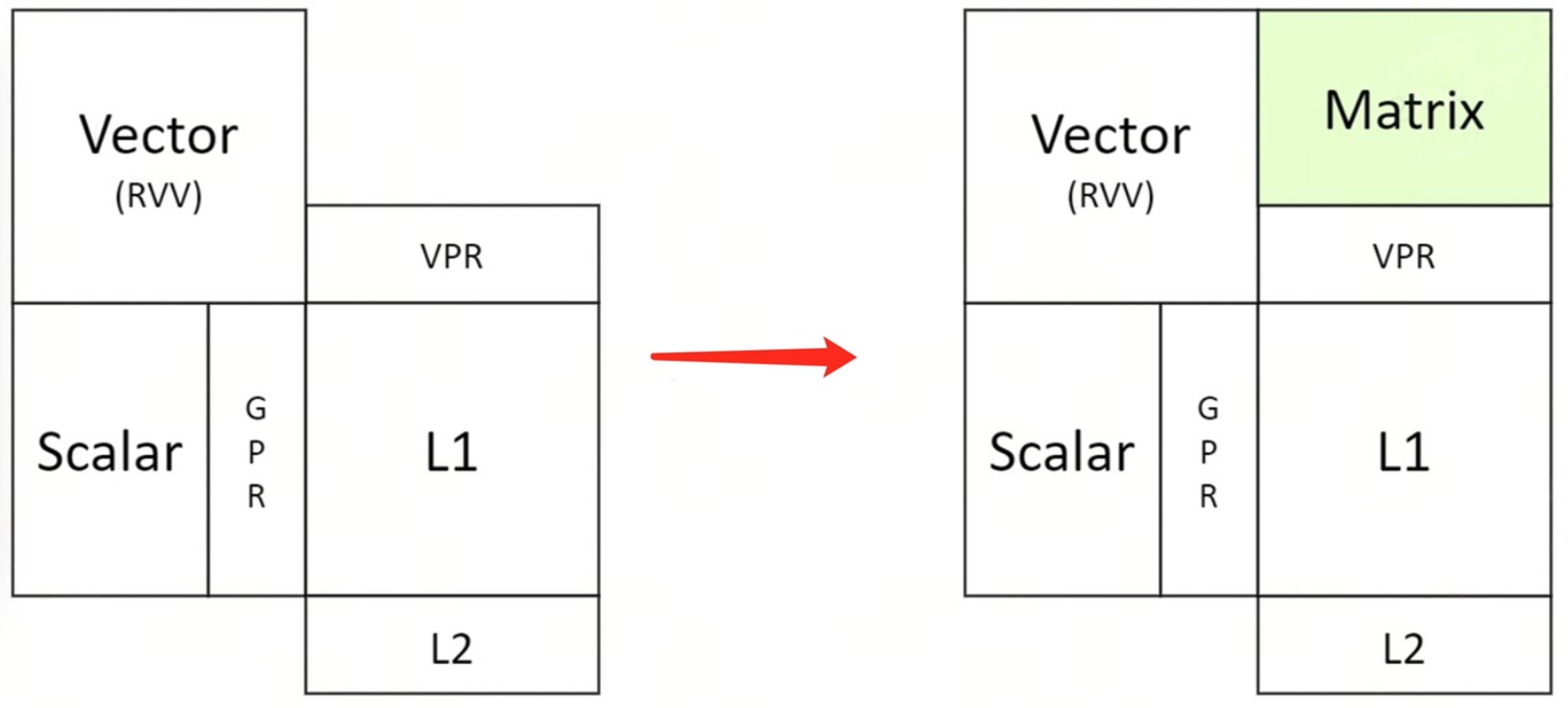 The detailed description of the computing power composition of the Intelligent Computing Core (single core) is as follows:
The detailed description of the computing power composition of the Intelligent Computing Core (single core) is as follows:
- Scalar computing power, using the RISC-V 64GCB standard instructions;
- Vector computing power, using the RISC-V Vector 1.0 standard instructions;
- Matrix computing power, provided in the form of dedicated acceleration instructions, using the RISC-V custom-1 coding space, and the operands and results are saved and reused in the VPR registers of RVV. For a detailed description of the extended instructions, you can refer to the instruction set manual RISC-V IME Extension Spec that we open sourced on github.
2. Computing Power Parameters
2.1 Theoretical Computing Power
In the X60 Intelligent Computing Core, the bit width of the RISC-V Vector is 256 bits, and the theoretical computing power of its matrix and vector is shown as follows:
- Matrix computing power:
- 0.5 TOPS/Core (Int8)
- 2 TOPS/Cluster (Int8)
- Vector computing power:
- 0.128 TOPS/Core (Int8)
- 0.5 TOPS/Cluster (Int8)
- 0.064 TOPS/Core (FP16)
- 0.25 TOPS/Cluster (FP16)
- 0.032 TOPS/Core (FP32)
2.2 Measured Computing Power
Based on the open-source project cpufp, the X60 Intelligent Computing Core in the K1 AI CPU is tested, and the measured data is as follows:
$./cpufp --thread_pool=[0]
Number Threads: 1
Thread Pool Binding: 0
---------------------------------------------------------------
| Instruction Set | Core Computation | Peak Performance |
| ime | vmadot(s32,s8,s8) | 511.53 GOPS |
| ime | vmadotu(u32,u8,u8) | 511.5 GOPS |
| ime | vmadotus(s32,u8,s8) | 511.53 GOPS |
| ime | vmadotsu(s32,s8,u8) | 511.51 GOPS |
| ime | vmadotslide(s32,s8,s8) | 511.51 GOPS |
| vector | vfmacc.vf(f16,f16,f16) | 66.722 GFLOPS |
| vector | vfmacc.vv(f16,f16,f16) | 63.936 GFLOPS |
| vector | vfmacc.vf(f32,f32,f32) | 33.36 GFLOPS |
| vector | vfmacc.vv(f32,f32,f32) | 31.968 GFLOPS |
| vector | vfmacc.vf(f64,f64,f64) | 16.679 GFLOPS |
| vector | vfmacc.vv(f64,f64,f64) | 15.985 GFLOPS |
---------------------------------------------------------------
For cluster 0 (with ime extension), 4 cores:
$./cpufp --thread_pool=[0-3]
Number Threads: 4
Thread Pool Binding: 0 1 2 3
---------------------------------------------------------------
| Instruction Set | Core Computation | Peak Performance |
| ime | vmadot(s32,s8,s8) | 2.046 TOPS |
| ime | vmadotu(u32,u8,u8) | 2.0462 TOPS |
| ime | vmadotus(s32,u8,s8) | 2.0461 TOPS |
| ime | vmadotsu(s32,s8,u8) | 2.0462 TOPS |
| ime | vmadotslide(s32,s8,s8) | 2.0461 TOPS |
| vector | vfmacc.vf(f16,f16,f16) | 266.88 GFLOPS |
| vector | vfmacc.vv(f16,f16,f16) | 255.75 GFLOPS |
| vector | vfmacc.vf(f32,f32,f32) | 133.43 GFLOPS |
| vector | vfmacc.vv(f32,f32,f32) | 127.85 GFLOPS |
| vector | vfmacc.vf(f64,f64,f64) | 66.709 GFLOPS |
| vector | vfmacc.vv(f64,f64,f64) | 63.935 GFLOPS |
---------------------------------------------------------------
For 2 clusters, 8 cores:
$./cpufp --thread_pool=[0-7]
Number Threads: 8
Thread Pool Binding: 0 1 2 3 4 5 6 7
---------------------------------------------------------------
| Instruction Set | Core Computation | Peak Performance |
| vector | vfmacc.vf(f16,f16,f16) | 533.65 GFLOPS |
| vector | vfmacc.vv(f16,f16,f16) | 511.45 GFLOPS |
| vector | vfmacc.vf(f32,f32,f32) | 266.89 GFLOPS |
| vector | vfmacc.vv(f32,f32,f32) | 255.75 GFLOPS |
| vector | vfmacc.vf(f64,f64,f64) | 133.42 GFLOPS |
| vector | vfmacc.vv(f64,f64,f64) | 127.86 GFLOPS |
---------------------------------------------------------------